服务输出日志太多、磁盘使用率高,导致服务无法启动!
1、背景
在今天凌晨半夜1点多的时候,突然收到公司的机器磁盘告警电话,打开企业微信一看,原来是机器的磁盘使用率达到了96%,吓得赶紧打开电脑处理一番....

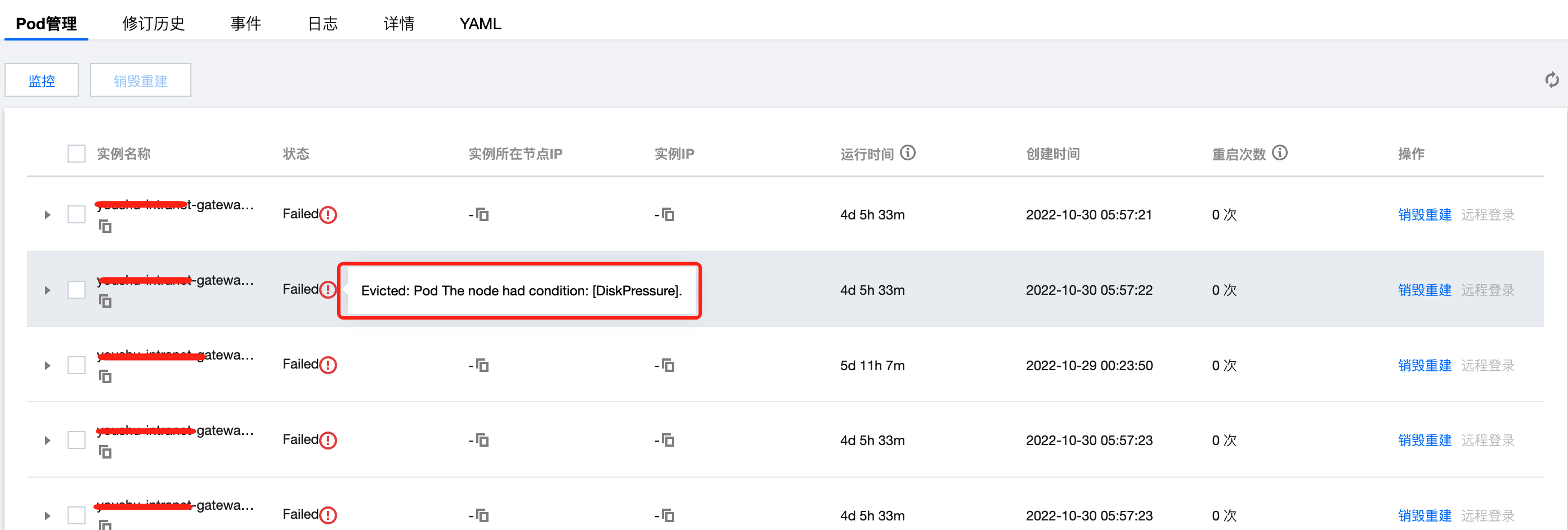
从分区目录/var/lib/docker目录看,初步判断是docker容器里输出的日志太多,导致磁盘被占满,服务无法正常启动,出现Evicted: Pod The node had condition: [DiskPressure].报错提示。
2、一探究竟
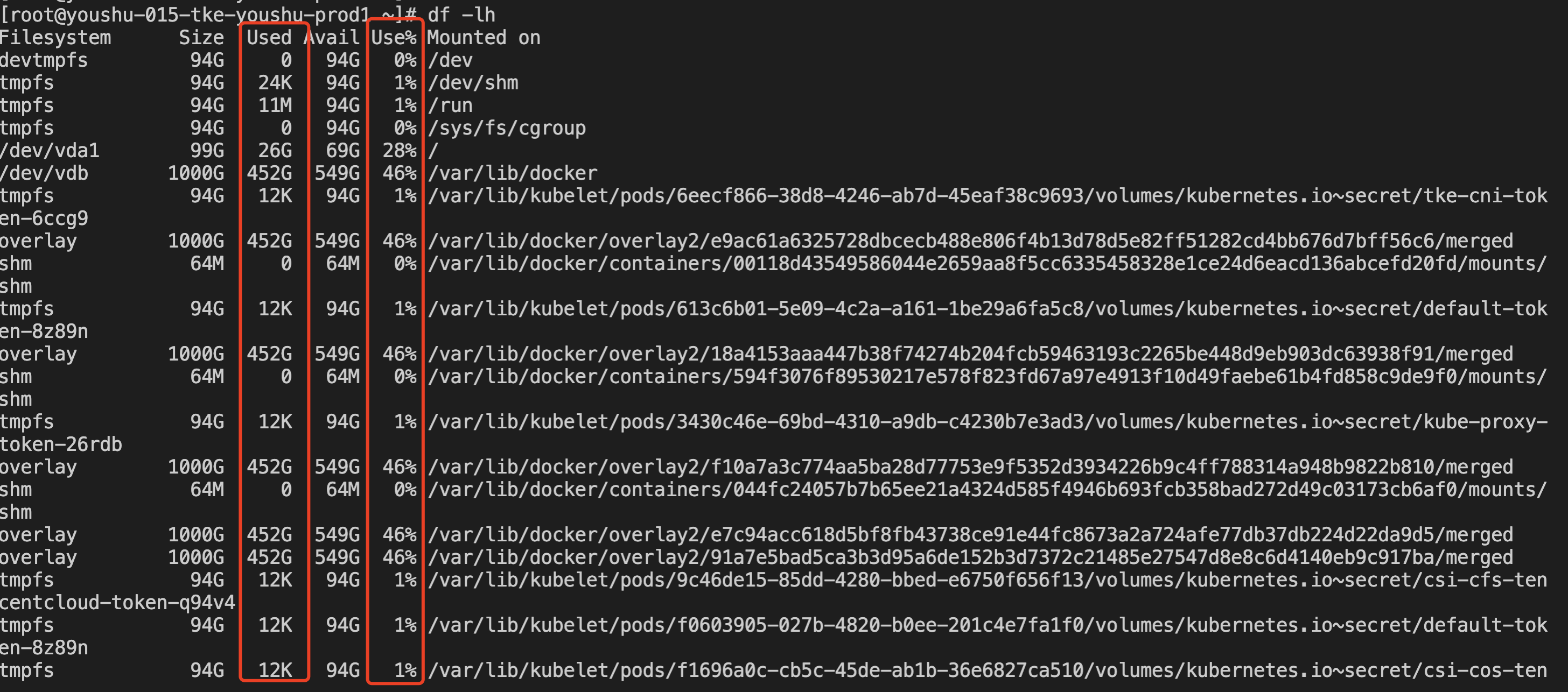
顺着这个思路排查具体是哪些文件占用太多的磁盘空间(以下图均为处理后的情况),使用df -lh查看服务器所有磁盘的使用情况:
进入其中一个使用率高的文件夹路径:
1cd /var/lib/docker/overlay2/e9ac61a6325728dbcecb488e806f4b13d78d5e82ff51282cd4bb676d7bff56c6
2cd /merged
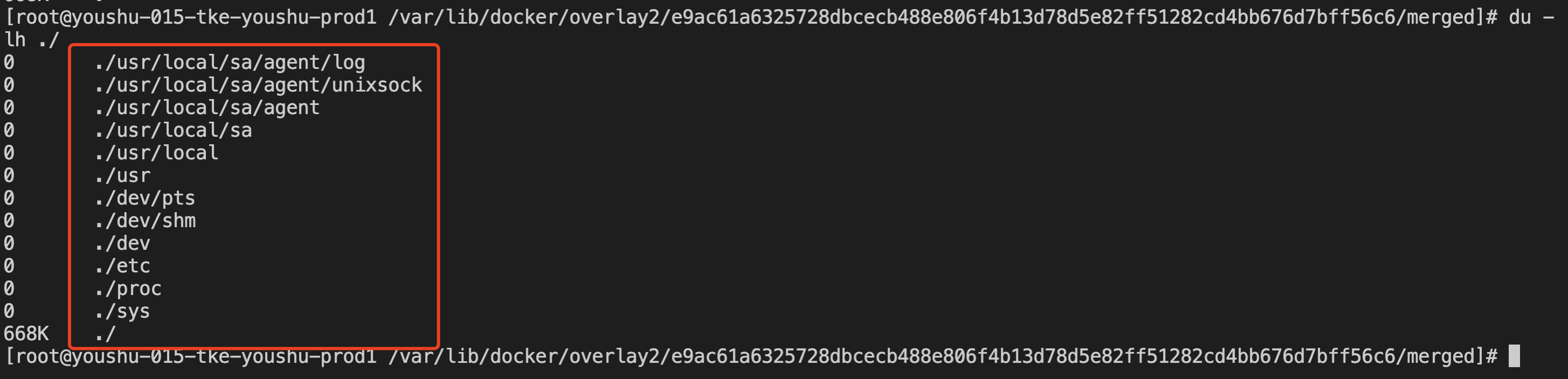
但进来后会发现这里只有几个文件夹:

使用du -lh ./命令后查询文件或文件夹占用大小,发现并没有
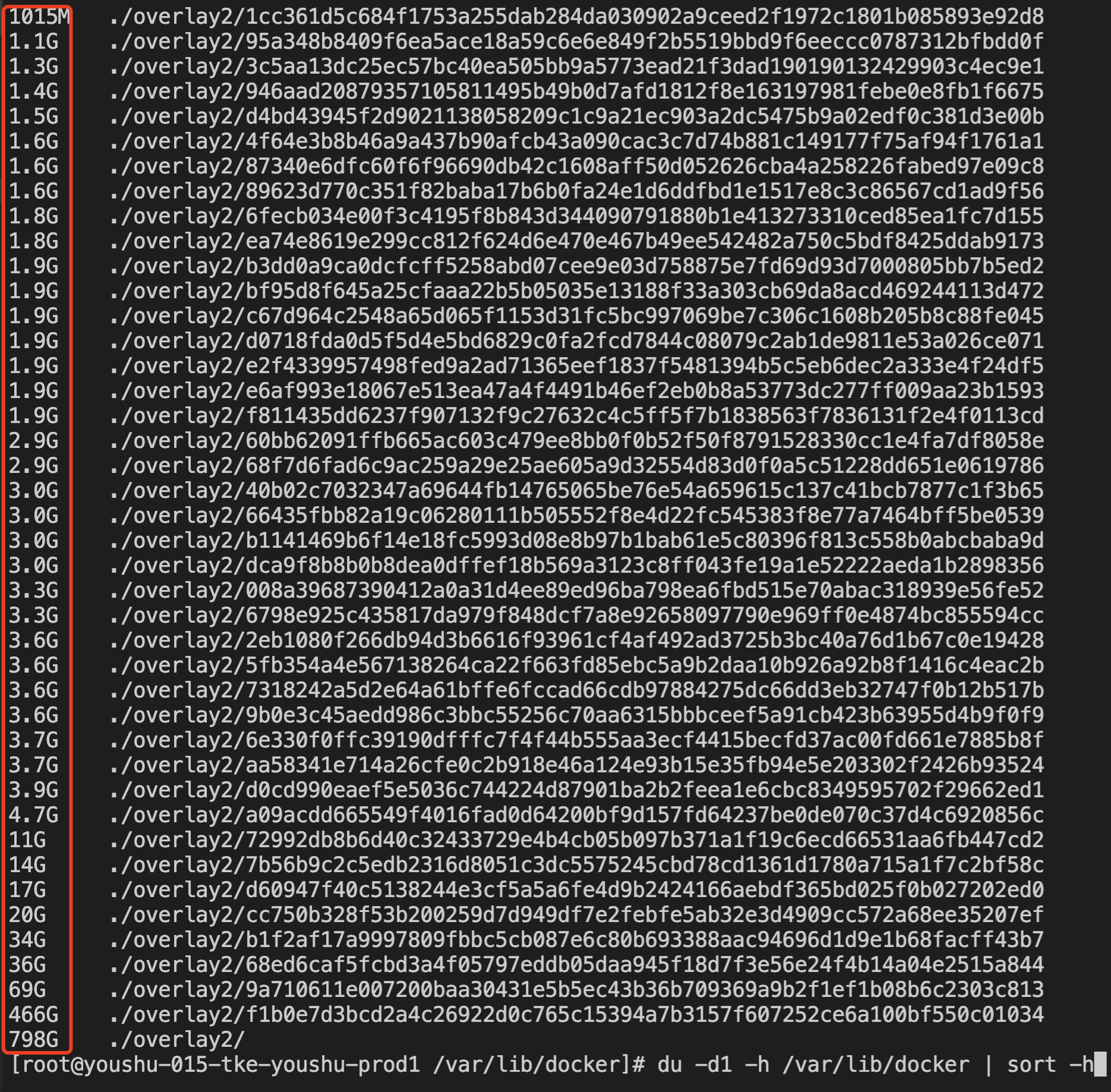
再查看一级目录的空间占用情况:
1du -d1 -h /var/lib/docker | sort -h
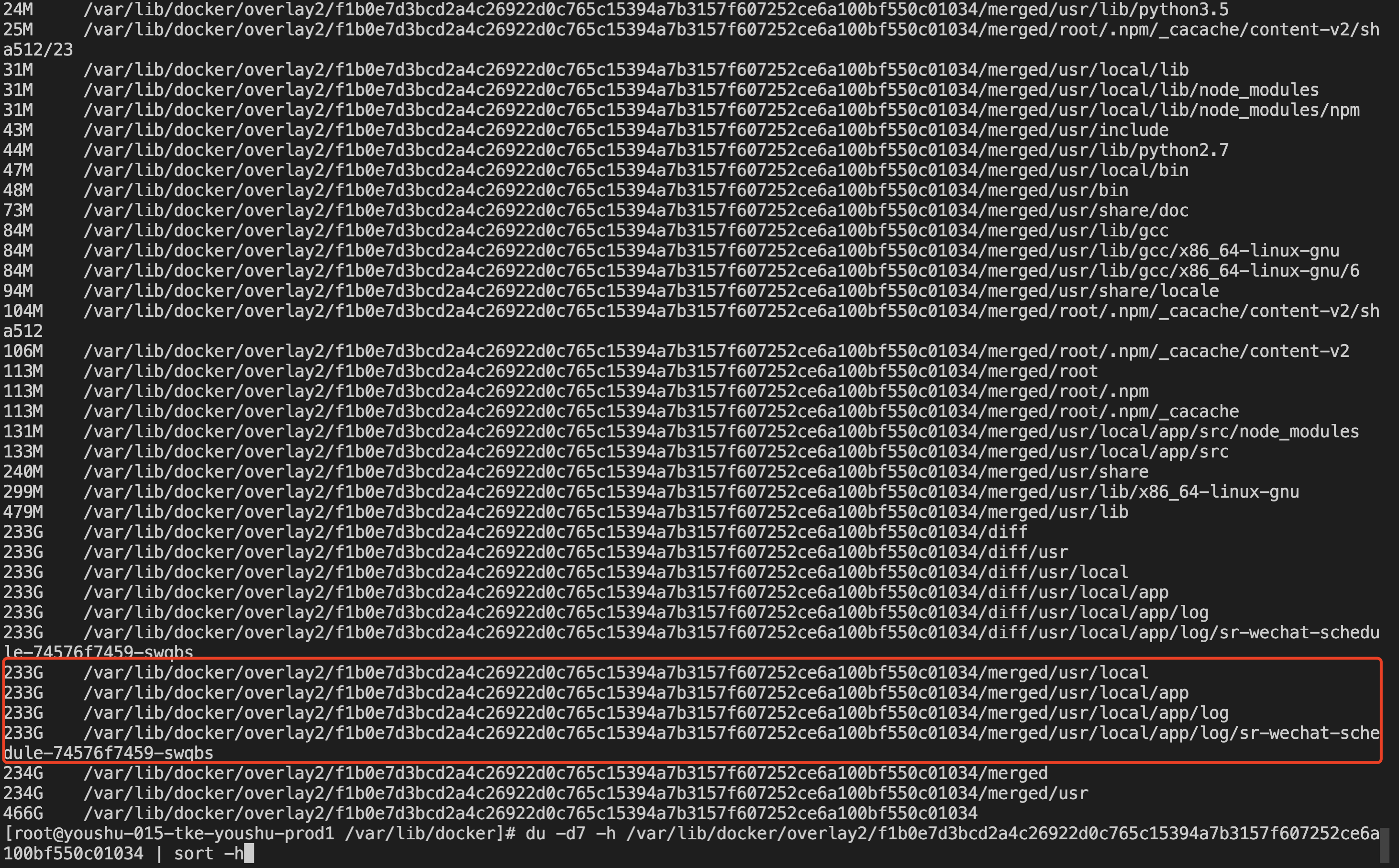
进一步分析7级目录占用的空间:
1du -d7 -h /var/lib/docker/overlay2/f1b0e7d3bcd2a4c26922d0c765c15394a7b3157f607252ce6a100bf550c01034 | sort -h
3、清理资源
选择需要清理的资源内容,并释放空间。
1cd /var/lib/docker/overlay2/f1b0e7d3bcd2a4c26922d0c765c15394a7b3157f607252ce6a100bf550c01034/merged/usr/local/app/log/sr-wechat-schedule-74576f7459-swqbs
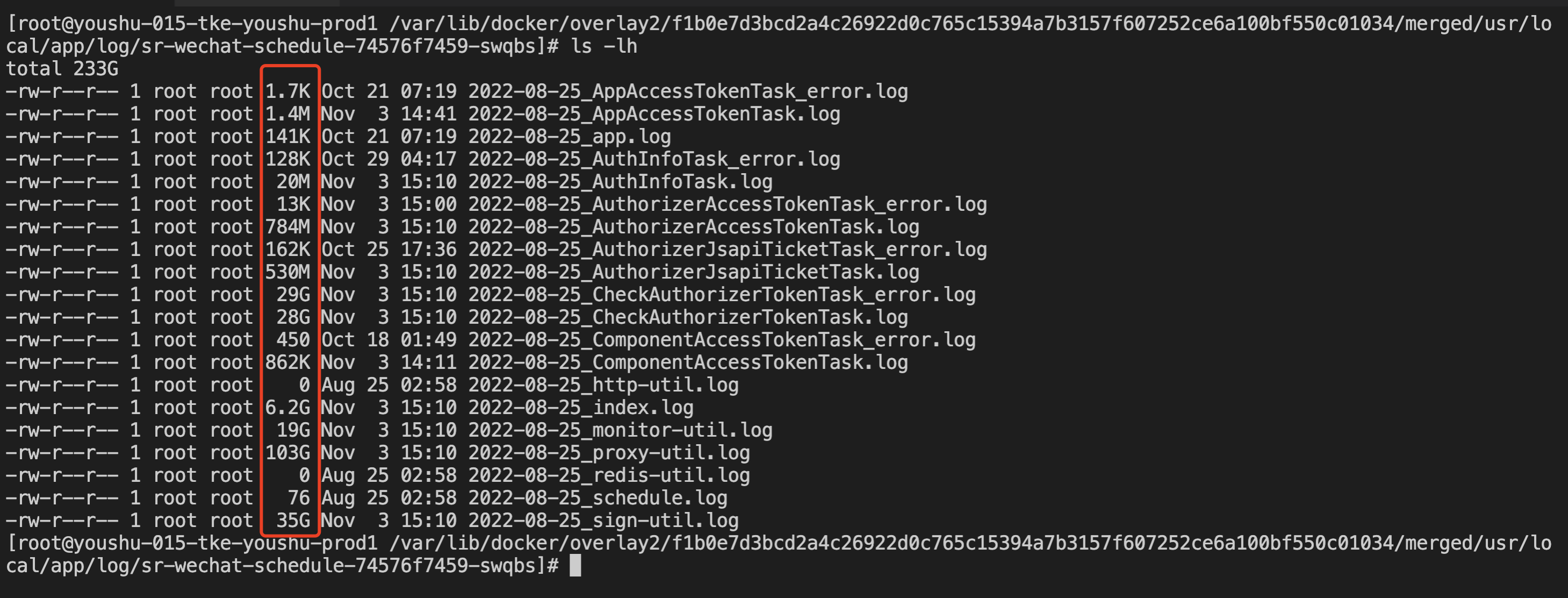
清空对应的文件内容,清理方式如下:
-
第一种:cat /dev/null > 2022-08-25_proxy-util.log
-
第二种:: > 2022-08-25_proxy-util.log
-
第三种:> 2022-08-25_proxy-util.log
-
第四种:echo "" > 2022-08-25_proxy-util.log
-
第五种:echo > 2022-08-25_proxy-util.log
1: > 2022-08-25_proxy-util.log
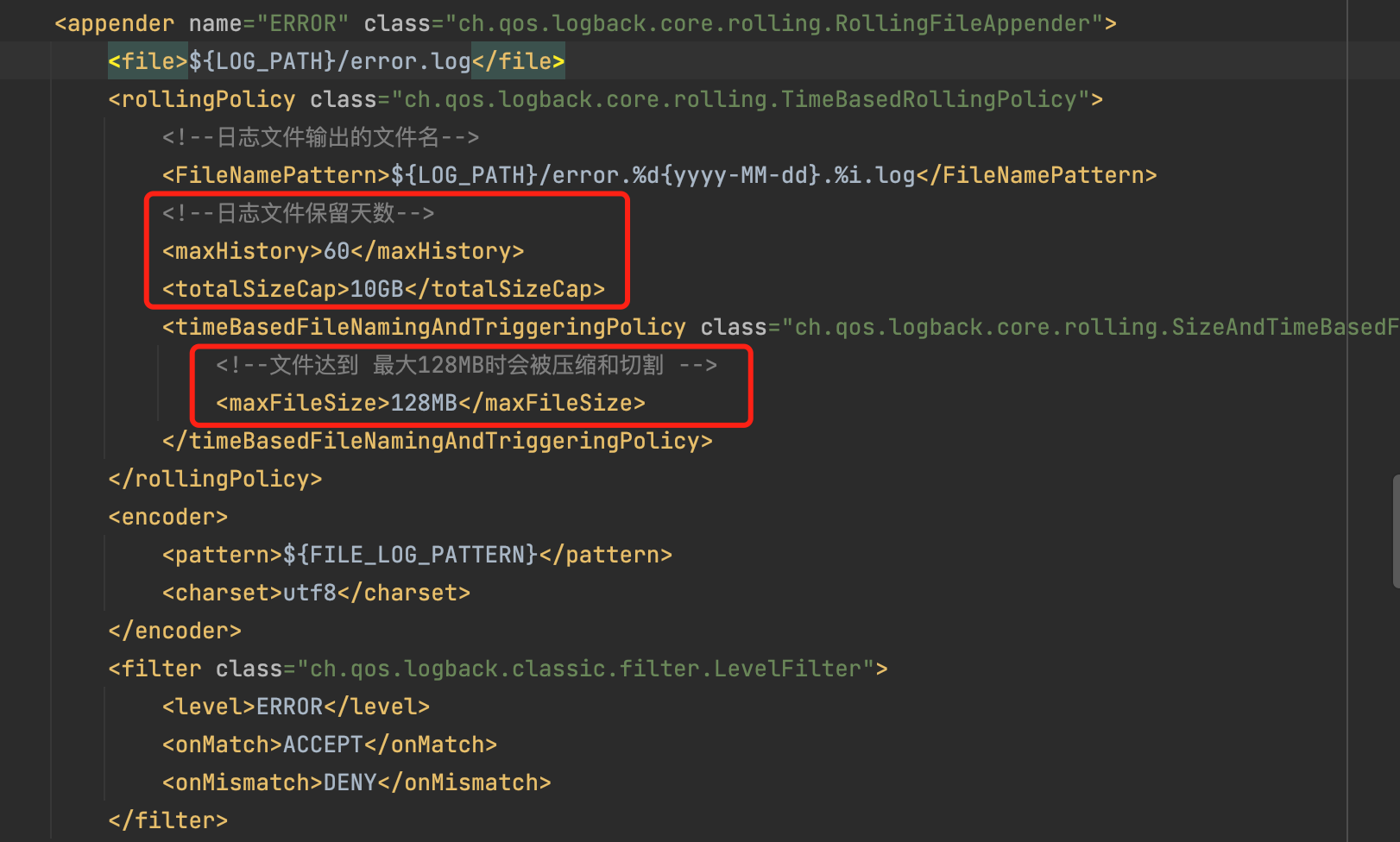
4、总结
上述是在Docker中文件占用磁盘空间多的处理方法,但该方法治标不治本,出现该问题的根本原因是没有对服务产生的日志文件做生命周期管理,导致磁盘一直保留周期长的日志文件,因此在项目中必须设置日志文件保留天数、压缩和切割,按需保留需要的日志即可,我们使用的logback作为日志框架,在logback.xml中会加入保留天数等: