clickhouse任务堵塞,导致服务不可用
1、问题现状
产品功能逻辑其实比较简单,执行 spark 任务并把 hive 表数据同步写入到 clickhouse 数据库表,每次执行前需删除操作分区下的所有数据并重新插入表,而在 spark 代码中使用的是 alter table 的操作。
2、根因分析
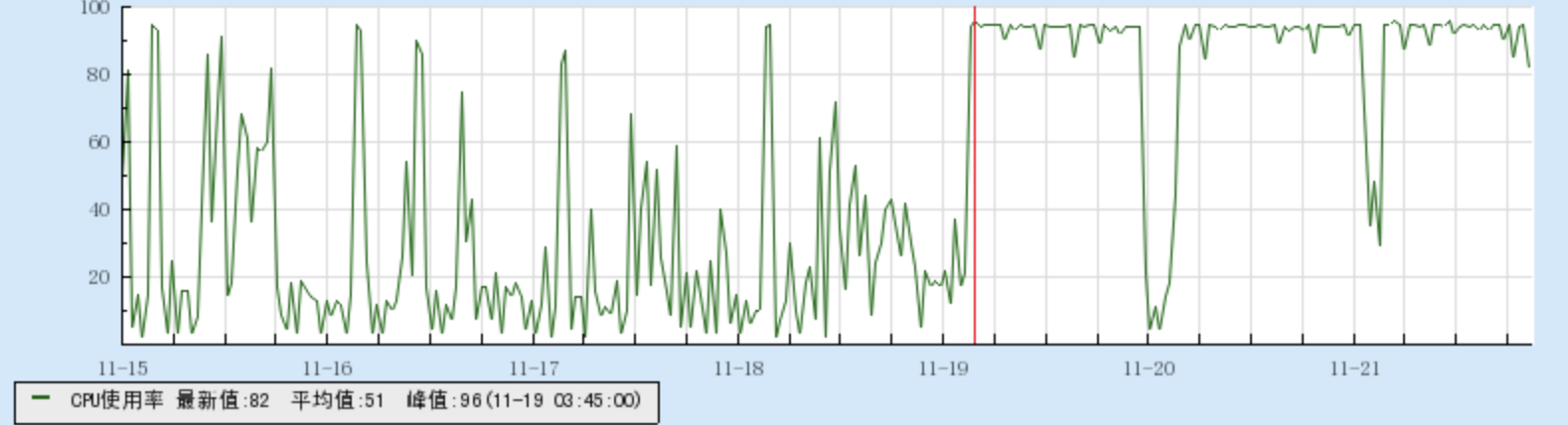
首先我们查看了集群机器状态,发现所有机器的 CPU 负载高居不下。
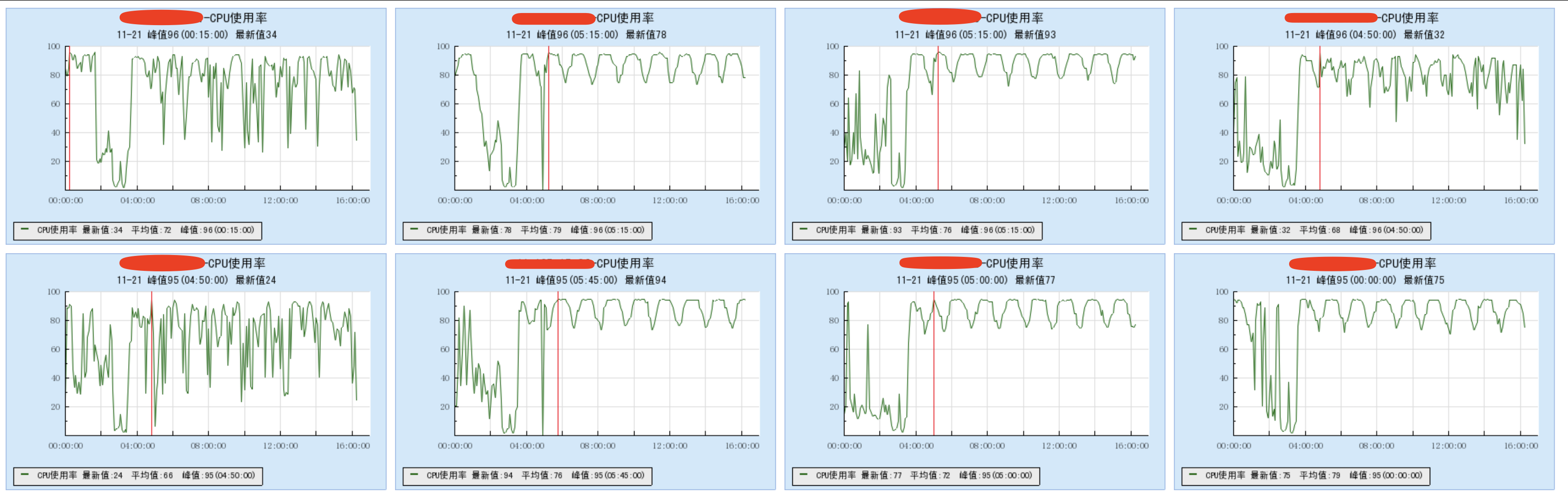
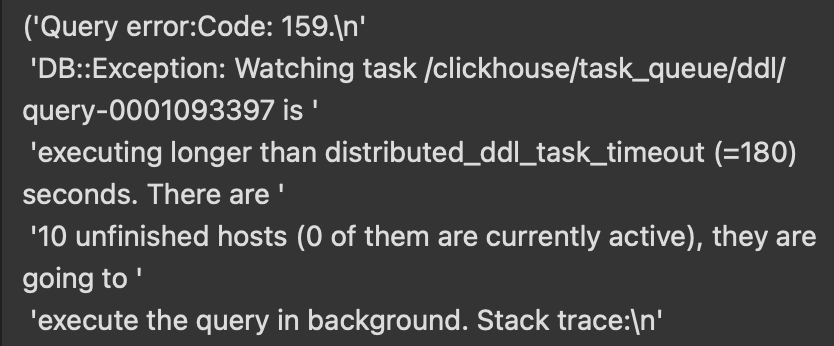
随后结合 spark 任务与后端接口的报错信息来看,初步推测是 clickhouse 的任务队列存在太多 ddl 操作了,导致连接超时。

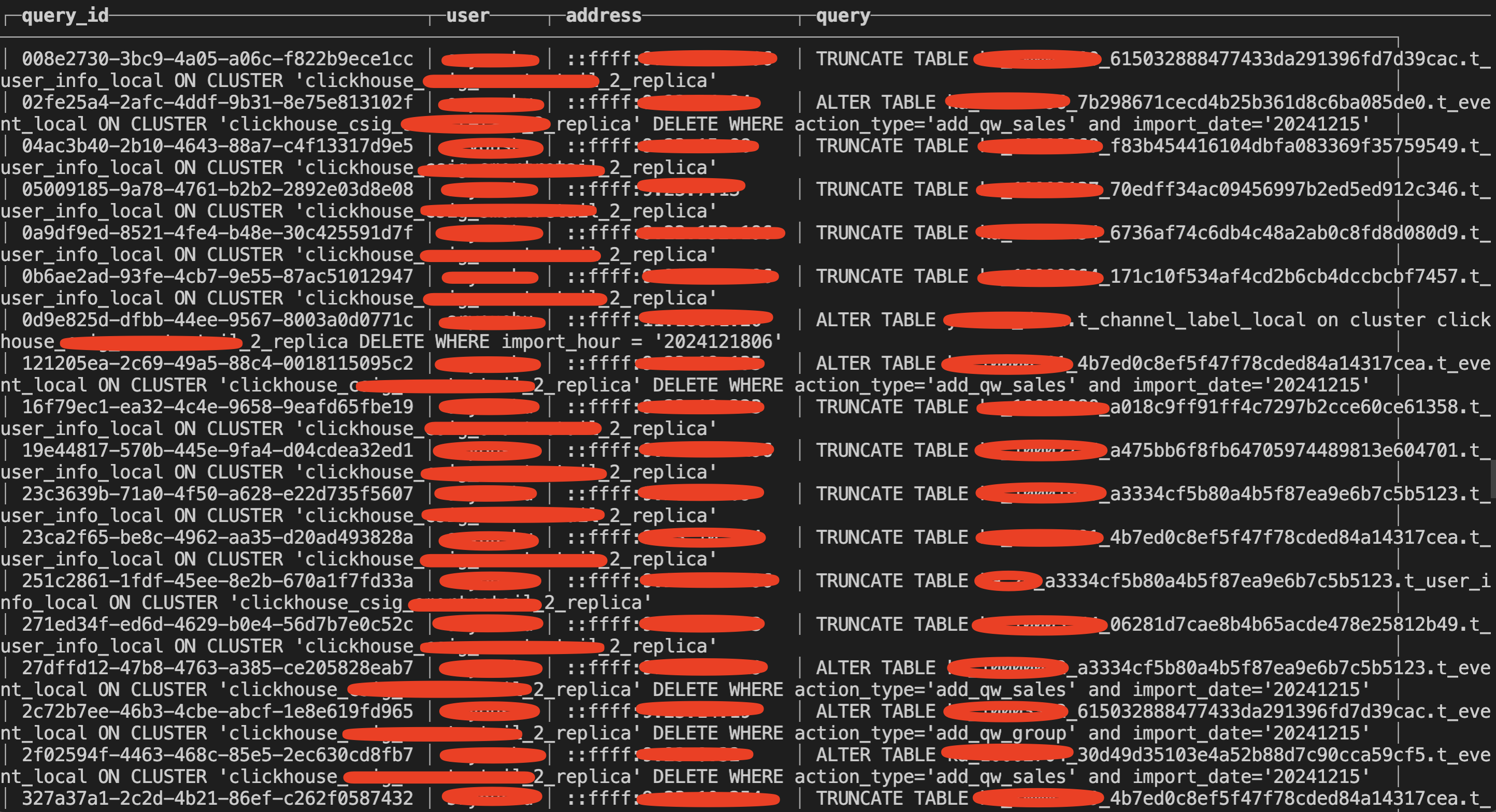
登录 clickhouse 数据库后,使用命令查询当前存在哪些 ddl ,真是不查不知道,一查吓一跳,全是 truncate table 语句或者 alter table delete 的操作。
1SELECT query_id, user, address, query FROM system.processes ORDER BY query_id;
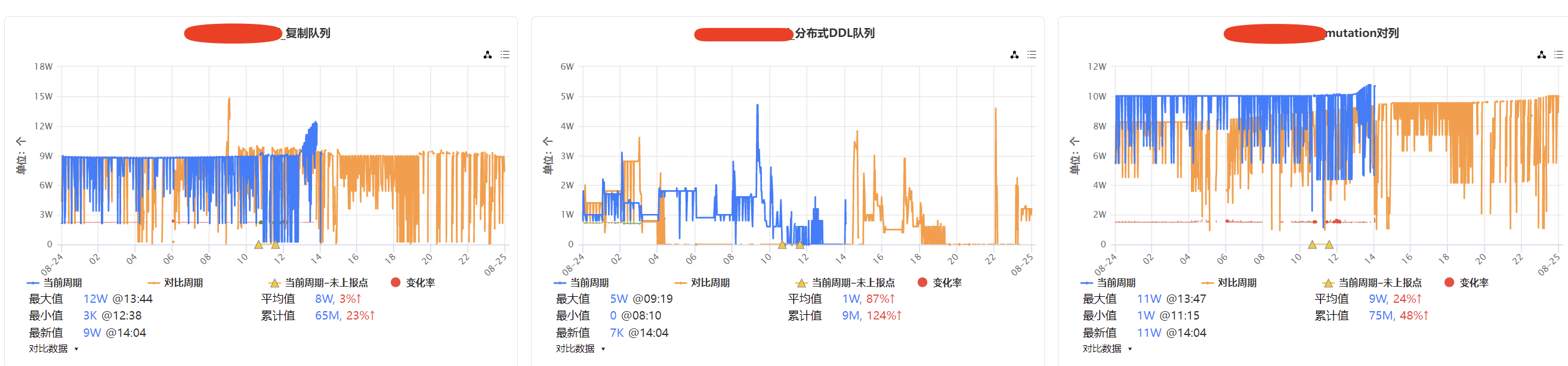
通过监控工具也发现整个 clickhouse 集群的复制队列、分布式队列、mutation 队列均出现阻塞情况,尤其是 mutation 队列。
3、临时处理
- 结合分析问题后,我们立刻先重启了
zookeeper服务,但重启发现现象并没有消退,原因是重启zookeeper后并不会消除clickhouse的队列任务,除此之外还有增量的任务进来,可能一下子把zookeeper打满。
- 统计 mutation 操作并执行清理操作

1SELECT query_id, user, address, query FROM system.processes ORDER BY query_id;
2
3select count(*) from system.mutations where is_done=0
4# 先把没用mutations操作给干掉
5KILL MUTATION where mutation_id = 'mutation_id';
6
7SELECT query_id, user, address, query FROM system.processes ORDER BY query_id;
8select * from system.processes where query_id='23e0d825-2730-4c7d-9051-3e623c22a051'
9
10
11终止查询
12KILL QUERY WHERE query_id='23e0d825-2730-4c7d-9051-3e623c22a051';
13KILL QUERY WHERE lower(query) like '%log_20214_minute_local%';
14
15# 在所有节点执行一遍,不要用分布式语句执行,就每个节点执行本地的,就是这个alter delete导致的,调大了ZK还是堵着,瞬间又会被打满
16
17KILL QUERY WHERE lower(query) like '%truncate%';
18# truncate语句不是关键,是alter语句,alter语句代价很大
19
20KILL MUTATION where table = 't_event_local';
21
22# 统计下database,通过database来清理任务
23SELECT database, table, count(*) FROM system.mutations where is_done=0 group by database, table;
最后需要在所有节点本地执行一遍清理操作,且不能用分布式语句执行,同时得保证没有新增任务写入。
1# 统计正在执行的 mutation 操作总数
2select count(*) from system.mutations where is_done=0
3SELECT command,is_done FROM system.mutations WHERE table = 'tablename'
4
5# 按照 query_id 查询 mutation 操作明细
6select query_id, user, address, query FROM system.processes order by query_id;
7
8# 按照数据库、表分组查询有多少 mutation 操作
9SELECT database, table, count(*) FROM system.mutations where is_done=0 group by database, table;
10
11# 终止 mutations 操作
12KILL MUTATION where mutation_id = 'mutation_id';
13
14# 按照表名称进行清理
15KILL MUTATION where table = 't_event_local';
16
17# 统计正在执行的查询操作
18select query_id, user, address, query from system.processes order by query_id;
19select * from system.processes where query_id='23e0d825-2730-4c7d-9051-3e623c22a051'
20
21# 终止查询操作
22KILL QUERY WHERE query_id='23e0d825-2730-4c7d-9051-3e623c22a051';
23KILL QUERY WHERE lower(query) like '%log_20214_minute_local%';
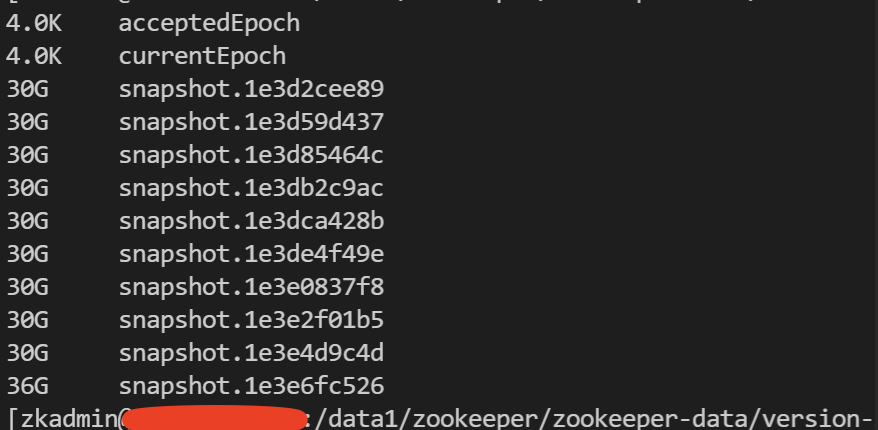
但执行清理 sql 任务时发现 zookeeper 宕机了,真的是一波未平,一波又起。

经过跟运维一番排查,得知 zookeeper 的 snapshot 太大了,我们把 zookeeper 都滚动重启一下,snapshot 大于分配的内存了,同时给 zookeeper 添加内存,重启完后再操作再执行清理。
重启完 zookeeper 后又重新登录集群的每个节点本地执行清理 mutation 任务的操作,直至清理完后页面才正常访问,最终我们把 spark 任务的 alter table delete 操作调整为 alter table drop partition 提升操作性能。
4、总结优化
clickHouse 中的 alter table delete 操作被认为是“很重的操作”,主要原因在于其执行机制和资源消耗。
在默认情况下,clickhouse 的alter update 、alter delete语句是异步的,这意味着更新操作是发生在后台的,不会立即见效,整个过程需先把删除的数据标记为待删除,然后任务执行删除,涉及到读取数据、删除操作、重新写入数据到文件系统,因此执行速度较慢。
其次我们业务上使用的 clickhouse 引擎是 MergeTree,在删除操作时需要读取整个分区的数据,而 clickhouse 是一个 OLAD 分析型数据库,数据通常不会频繁更新,在设计上没有对频繁更新、删除的操作进行优化。