Spring Cloud Gateway 日志内容乱码问题
1、问题偶现
最近在排查线上问题时,发现网关打印的响应数据日志偶尔出现乱码现象,但实际上接口下发给客户端的是正常的,无法在服务端查看其原始数据,进一步影响排查问题的效率、解决问题。
2、前思后想
经过一番排查定位后,了解到 spring cloud gateway 的 Mono<DataBuffer>.flatMap()方法在获取数据时,若响应数据较大则只会取其中的一部分,导致日志显示不完成出现乱码,原代码逻辑如下:
1private static class HoldBodyResponseDecorator extends ServerHttpResponseDecorator {
2
3 private byte[] body;
4
5 public HoldBodyResponseDecorator(ServerHttpResponse response) {
6 super(response);
7 }
8
9 @Override
10 public Mono<Void> writeWith(Publisher<? extends DataBuffer> data) {
11 // 这种在响应较大的情况下实际上只取了其中一部分,会导致乱码
12 Mono<DataBuffer> bufferMono = DataBufferUtils.join(data);
13 var clonedMono = bufferMono.flatMap(buffer -> {
14 try {
15 body = new byte[buffer.readableByteCount()];
16 buffer.read(body);
17
18 return Mono.just(buffer);
19 } catch (Exception e) {
20 log.warn("error occurred while read response body on AccessLogFilter.", e);
21 return Mono.just(buffer);
22 } finally {
23 buffer.readPosition(0);
24 }
25 });
26 return super.writeWith(clonedMono);
27 }
28
29 @Override
30 public Mono<Void> writeAndFlushWith(Publisher<? extends Publisher<? extends DataBuffer>> body) {
31 return writeWith(Flux.from(body).flatMapSequential(p -> p));
32 }
33 }
经过改造后,把上述的逻辑改为如下,并加上 mediaType 是否为 application/json 的格式:
1 private static class HoldBodyResponseDecorator extends ServerHttpResponseDecorator {
2
3
4 private byte[] body;
5
6 public HoldBodyResponseDecorator(ServerHttpResponse response) {
7 super(response);
8 }
9
10 @Override
11 public Mono<Void> writeWith(Publisher<? extends DataBuffer> publisher) {
12
13 MediaType mediaType = getDelegate().getHeaders().getContentType();
14 boolean isApplicationJsonMedia = MediaType.APPLICATION_JSON.isCompatibleWith(mediaType);
15 DataBufferFactory bufferFactory = getDelegate().bufferFactory();
16 //只处理为 application/json 的 mediaType
17 if (publisher instanceof Flux && isApplicationJsonMedia) {
18 Flux<? extends DataBuffer> fluxBody = Flux.from(publisher);
19 return super.writeWith(fluxBody.buffer().map(dataBuffer -> {
20 DataBuffer join = null;
21 try {
22 //如果响应过大,会进行截断,出现乱码,通过 join 方法可以合并所有的流
23 DataBufferFactory dataBufferFactory = DefaultDataBufferFactory.sharedInstance;
24 join = dataBufferFactory.join(dataBuffer);
25 body = new byte[join.readableByteCount()];
26 join.read(body);
27
28 return bufferFactory.wrap(body);
29 } finally {
30 if (join != null) {
31 //释放掉内存
32 DataBufferUtils.release(join);
33 }
34 }
35 }));
36 }
37 return super.writeWith(publisher);
38 }
39
40 @Override
41 public Mono<Void> writeAndFlushWith(Publisher<? extends Publisher<? extends DataBuffer>> body) {
42 return writeWith(Flux.from(body).flatMapSequential(p -> p));
43 }
44 }
但修改部署到测试环境后,再查看日志还是发现内容显示乱码,疑惑:代码上不是已经全部内容聚合一块再打印出来吗?

3、眉头一皱
**进一步思考:**有没有可能原本响应的内容就已经经过编码处理?按照这个思路排查,通过抓包浏览器的请求头及响应头发现接口响应回来的是经过 gzip 算法压缩处理过的。
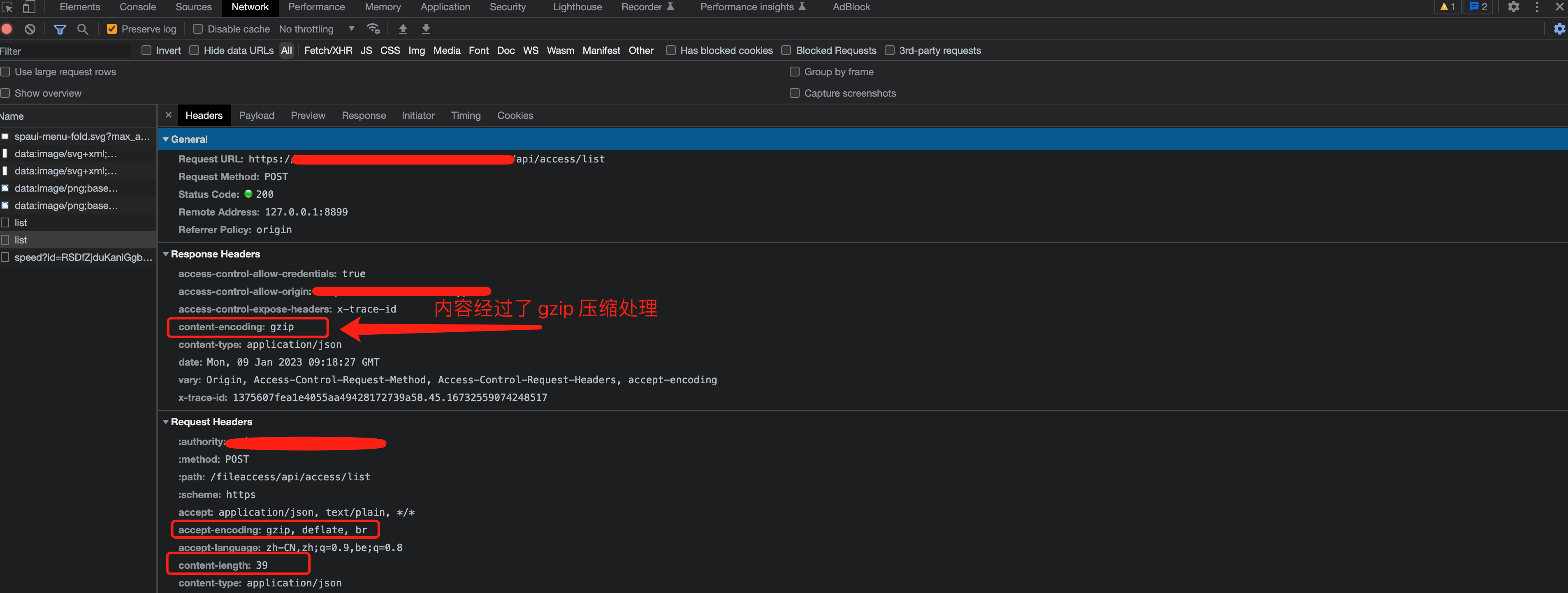
因此,猜测在网关中打印的响应日志也是经过 gzip 算法压缩处理过的,需要经过解码后才能正常显示其原始内容,接下验证这猜想,在代码逻辑加上对响应头的 Content-Encoding 字段值判断是否为 gzip,若是则进行解压缩处理,还原其内容即可。
1 private static class HoldBodyResponseDecorator extends ServerHttpResponseDecorator {
2
3
4 private byte[] body;
5
6 public HoldBodyResponseDecorator(ServerHttpResponse response) {
7 super(response);
8 }
9
10 @Override
11 public Mono<Void> writeWith(Publisher<? extends DataBuffer> publisher) {
12
13 MediaType mediaType = getDelegate().getHeaders().getContentType();
14 boolean isApplicationJsonMedia = MediaType.APPLICATION_JSON.isCompatibleWith(mediaType);
15 DataBufferFactory bufferFactory = getDelegate().bufferFactory();
16
17 if (publisher instanceof Flux && isApplicationJsonMedia) {
18 Flux<? extends DataBuffer> fluxBody = Flux.from(publisher);
19
20 return super.writeWith(fluxBody.buffer().map(dataBuffer -> {
21 DataBuffer join = null;
22 try {
23 //如果响应过大,会进行截断,出现乱码,然后看api DefaultDataBufferFactory有个join方法可以合并所有的流,乱码的问题解决
24 DataBufferFactory dataBufferFactory = DefaultDataBufferFactory.sharedInstance;
25 join = dataBufferFactory.join(dataBuffer);
26 body = new byte[join.readableByteCount()];
27 join.read(body);
28
29 //判断响应头的encoding-type是否为gzip,如果是则进行解压缩处理
30 List<String> encodingList = getDelegate().getHeaders().get(HttpHeaders.CONTENT_ENCODING);
31 String zipEncodingType = gzipMessageBodyResolver.encodingType();
32 boolean zip = encodingList != null && encodingList.contains(zipEncodingType);
33
34 DataBuffer wrapDataBuffer = bufferFactory.wrap(body);
35
36 body = zip ? gzipMessageBodyResolver.decode(body) : body;
37 return wrapDataBuffer;
38 } finally {
39 if (join != null) {
40 //释放掉内存
41 DataBufferUtils.release(join);
42 }
43 }
44 }));
45 }
46 return super.writeWith(publisher);
47
48
49 }
50
51 @Override
52 public Mono<Void> writeAndFlushWith(Publisher<? extends Publisher<? extends DataBuffer>> body) {
53 return writeWith(Flux.from(body).flatMapSequential(p -> p));
54 }
55 }
4、屡试屡验
重新发到测试环境验证一把,发现不再乱码了,接口的响应内容都能正常显示:

但为什么网关上的日志需要手动解压缩处理才能正常显示,而浏览器访问页面时,能自动处理并正常显示?
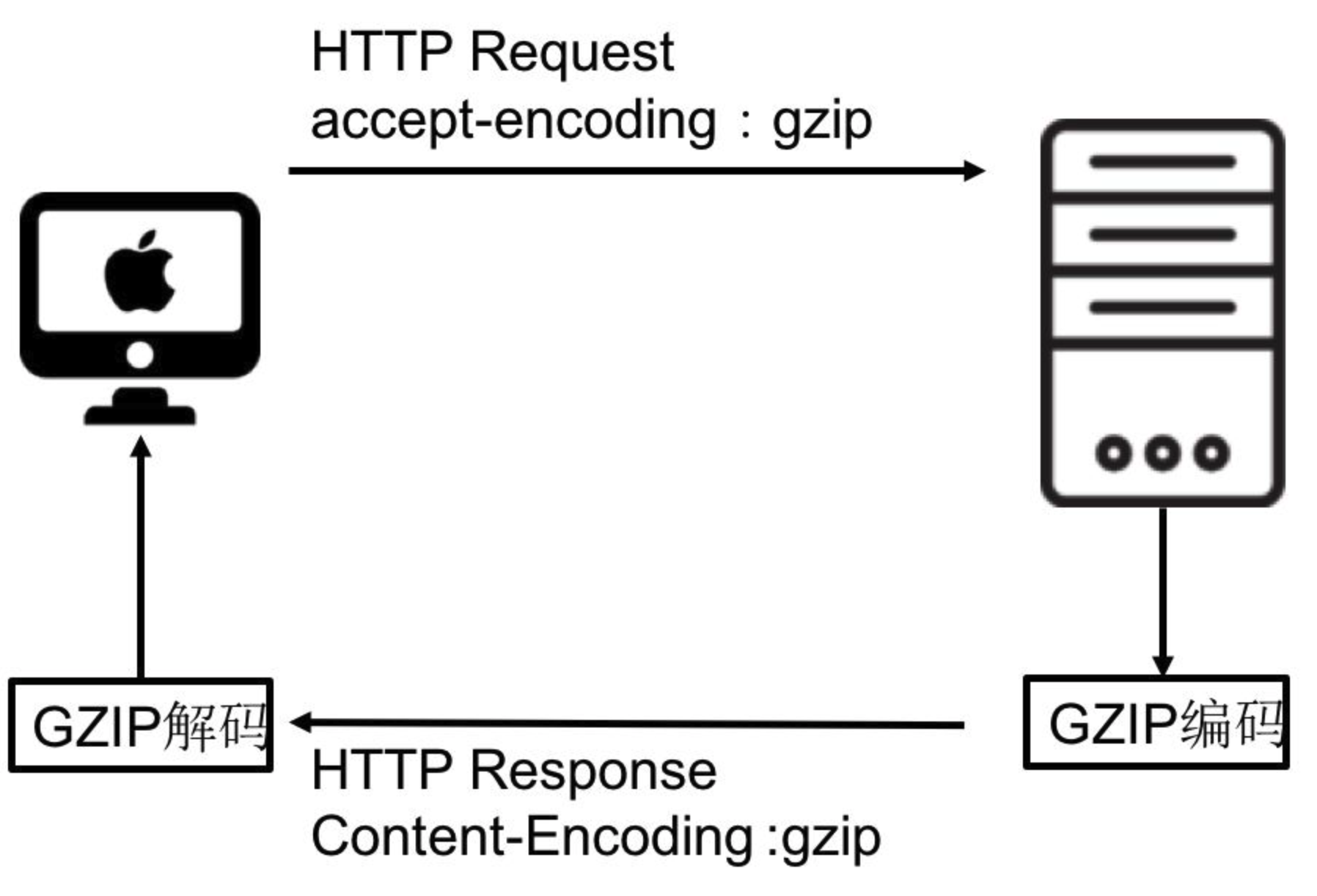
通过上图可知客户端和服务器之间如何进行 gzip 通信的:
-
浏览器请求页面及后端接口时,在
request header中设置属性accept-encoding : gzip,表明浏览器支持gzip,并期望使用 gzip 算法解压缩响应内容。 -
服务器收到浏览器发送的请求后,判断浏览器是否支持
gzip压缩(通过 accept-encoding信息),如果支持gzip,则向浏览器传送经过 gzip 压缩过的内容;若不支持则向浏览器发送未经压缩的内容,一般情况下,浏览器和服务器都支持gzip,在响应头response headers会返回包含content-encoding : gzip的字段值。 -
浏览器接收到服务器的响应后,判断响应内容是否被压缩过,如果被压缩则解压缩内容再显示页面内容。
5、最后总结
在项目使用 spring cloud gateway 网关时,所有的后端接口都会经过网关服务,需要打印出接口的关键信息到日志文件中,如果打印的日志信息是乱码,无疑会影响排查问题的效率,同时 spring cloud gateway 获取响应数据时,需要把多段数据流聚合在一起,防止响应数据量大导致数据截断问题。
浏览器自身是支持 gzip 解压缩能力的,因此使用浏览器访问页面时,并不会出现页面数据乱码问题,而我们在 spring cloud gateway 网关拦截器获取响应内容时,需手动判断响应的内容是否经过 gzip 压缩,再把响应内容输出到日志文件中,防止出现 gzip 引起的乱码问题,同时提高传输效率。